
Real Waste ML Classification
Teaching Machines to See Trash: Our Journey with Deep Learning and Waste Classification

It started with a simple, yet daunting question: what if machines could look at trash and know exactly where it belongs?
Every day, millions of tons of waste are produced worldwide. Most of it ends up in landfills, much of it recyclable, and some even biodegradable. The problem isn’t just the waste—it’s the sorting. Traditional methods of waste management rely heavily on human labor: tedious, error-prone, and often inefficient. And that’s where our project began.
We wanted to build something that could make waste classification faster, smarter, and—most importantly—automatic.
The Beginning: Choosing the Dataset
Our journey started with the Real Waste Dataset from UCI, a collection of 4,752 images divided into 9 waste categories:
Cardboard – 461 images
Food Organics – 411 images
Glass – 420 images
Metal – 790 images
Miscellaneous Trash – 495 images
Paper – 500 images
Plastic – 921 images
Textile Trash – 318 images
Vegetation – 436 images
Each image measured 524 × 524 pixels with 3 RGB channels, which meant our neural networks had to process high-dimensional data. Before feeding the dataset into the models, we standard-scaled it to ensure faster convergence during training.
The Metrics that Mattered
We didn’t want just accuracy—we wanted a balanced picture.
So, we evaluated our models using:
Categorical Cross-Entropy Loss: to measure how far our predictions were from reality.
F1 Score: the harmonic mean of precision and recall, ensuring we weren’t just good at some classes while failing miserably at others.
The Experiments: Building & Training Models
We split the dataset: 80% for training and 20% for validation. Then came the real grind—training not one, but four different CNN architectures:
Custom CNN (Our Own Model)
Built from scratch.
Served as a baseline for comparison.
VGG 19
A deep, well-known architecture, but surprisingly under-explored in Kaggle waste classification notebooks.
Inception V3
Transfer learning with a twist:
First, we trained only the top layer for 10 epochs.
Then, we fine-tuned by unfreezing some of the pre-trained layers and continuing for another 10 epochswith a reduced learning rate.
MobileNets V1.0
Lightweight, fast, and efficient.
Also, not previously explored in Kaggle notebooks for this dataset.
To make our models smarter, we added:
Step Learning Rate Scheduling – dynamically adjusting the learning rate during training.
Model Checkpoints – automatically saving the best-performing weights whenever the validation loss improved.
All models were trained using the Adamax optimizer with CrossEntropy loss.
The Results: Which Model Won?
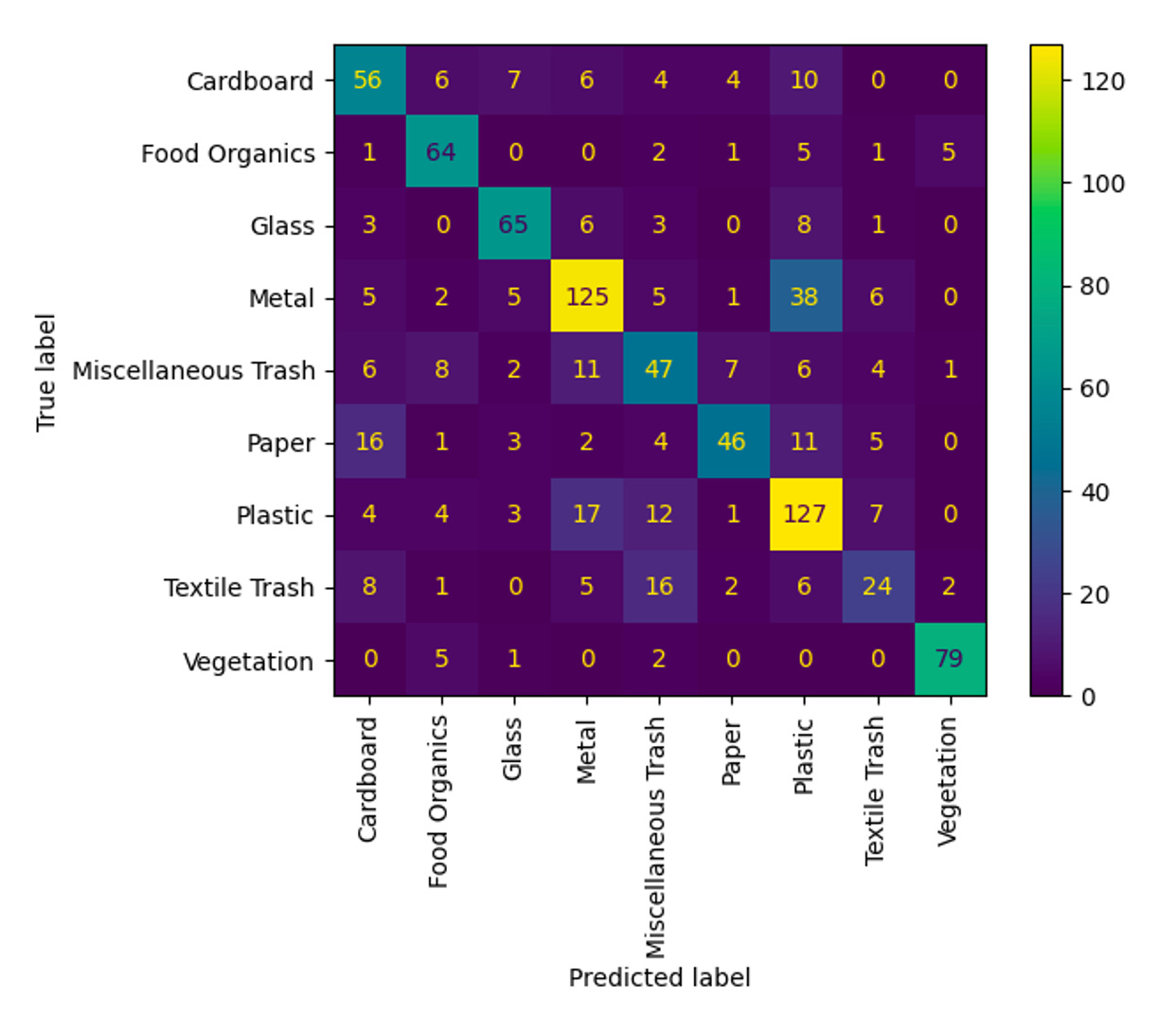
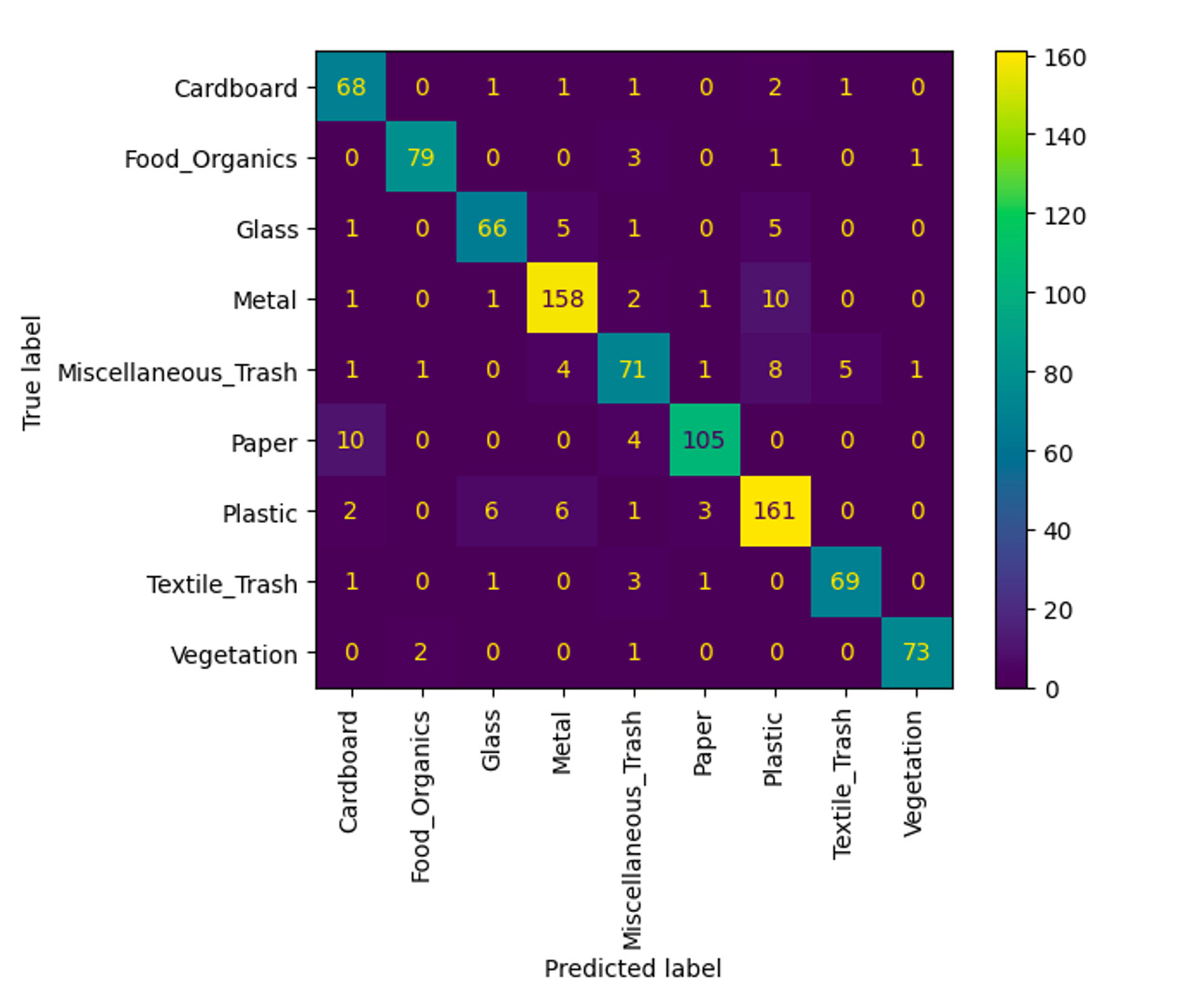
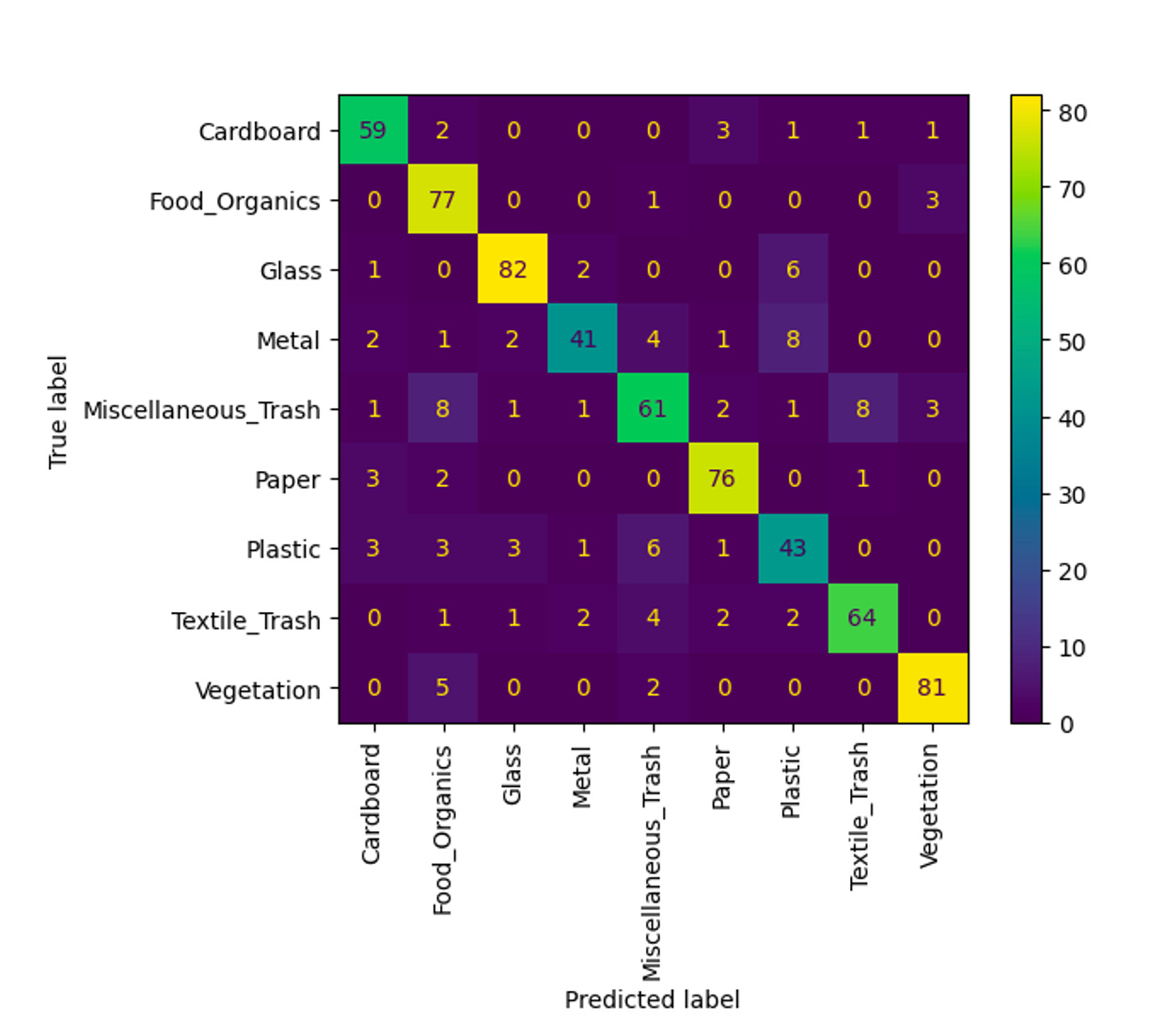
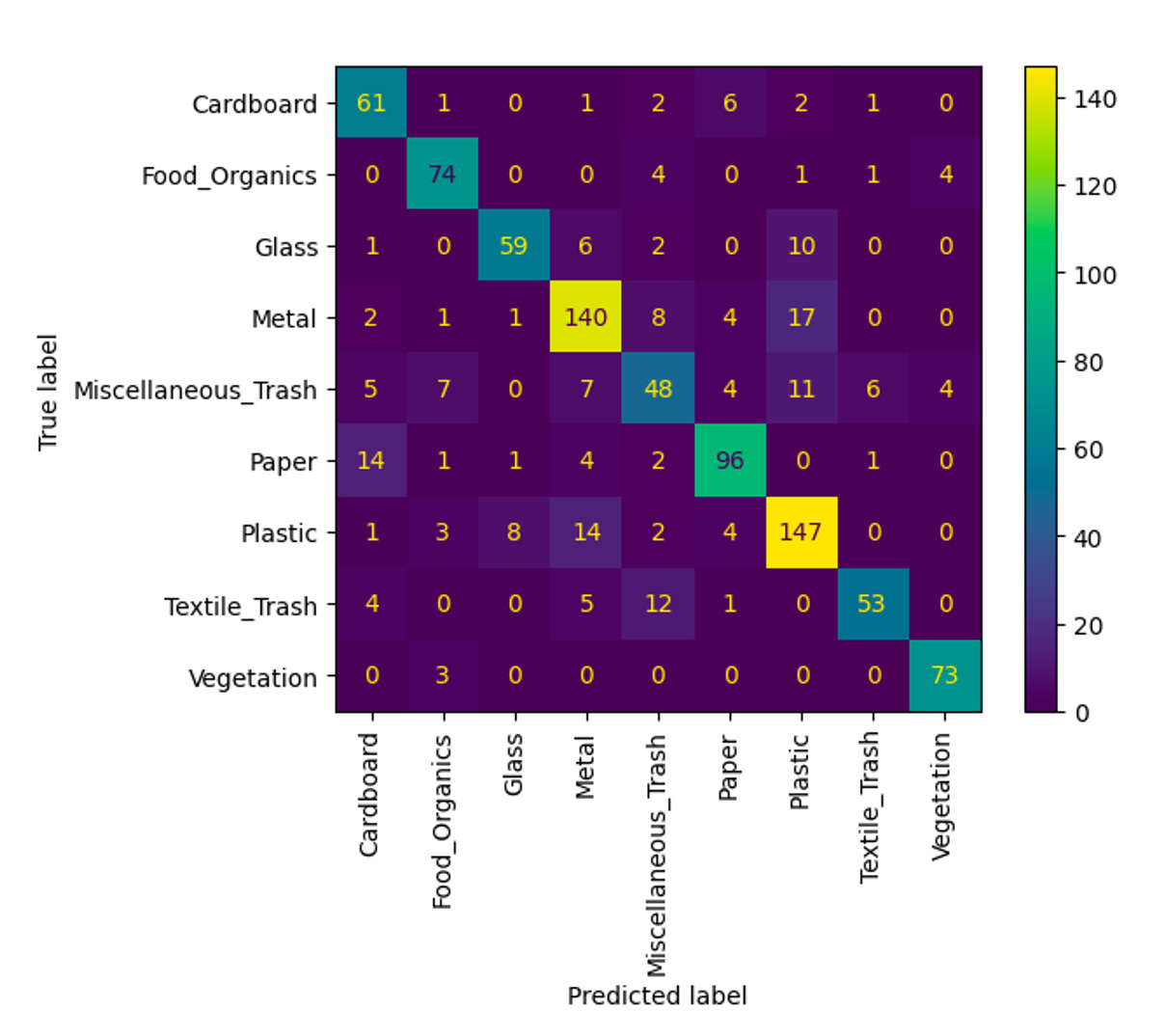
After weeks of experimentation, here’s how the models stacked up:
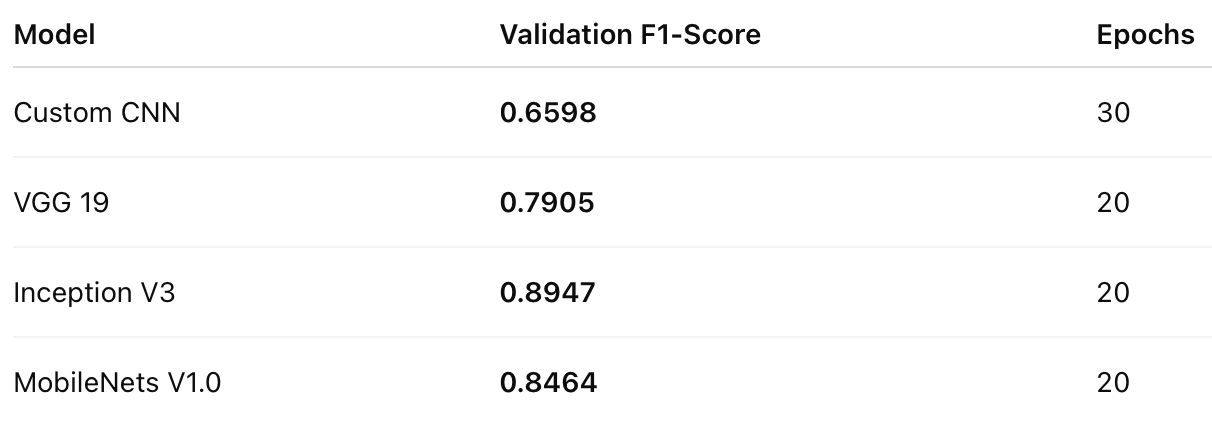
The clear winner was Inception V3, achieving the highest F1-score. But there was a catch: it was also the slowest model. On the other hand, MobileNets V1.0 delivered an impressive balance—high accuracy with significantly faster performance, thanks to its depthwise separable convolution layers.
What We Learned
In the end, our project proved that deep learning can dramatically improve waste classification. While Inception V3shined in accuracy, MobileNets V1.0 showed us that speed and efficiency can’t be overlooked—especially if such a system is ever to be deployed in real-world recycling plants.
This wasn’t just an experiment—it was a step toward rethinking how technology can tackle one of the world’s oldest problems: trash.
The Team Behind the Work
Amish Faldu (af557)
Sneh Vora (sv992)
Palak Pabani (pp872)
Want to Explore More?
📂 Dataset: UCI Real Waste Dataset
💻 Code: Google Drive Repository
🎥 Project Video: Link
👉 This is just the beginning. Imagine a world where waste bins have eyes—powered by AI—to sort your trash for you. That’s not science fiction anymore. It’s where we’re headed.